



Native PDF text extraction relies on font and encoding data. OCR tools convert scanned PDF images into searchable text, enabling efficient data handling and analysis. This insightful blog post will help you explore practical techniques for running OCR on PDF and extracting your text without any problems.
What Do You Need to Install Before OCRing PDF in Python
Optical Character Recognition (OCR) technology empowers computers to extract text from images or scanned documents, streamlining data processing and analysis by eliminating manual transcription. Python offers several OCR libraries that facilitate text extraction from PDF files.
Python's PDF OCR libraries enable developers to convert PDF pages into images and subsequently extract text, leveraging Python's capabilities to automate data extraction tasks efficiently and effectively from large volumes of documents.
Before you get started to extract text from scanned PDFs, ensure you have the following installed on your system or device.
The necessary requirements for OCR PDF in Python include:
- ocrmypdf==12.2.0
- camelot-py==0.9.0
- Ghostscript
Additional requirements:
- Pillow==8.2.0
- pytesseract==0.3.7
How to OCR PDF in Python
Optical Character Recognition (OCR) is a crucial electronic tool for converting scanned images or handwritten text into editable computer files. Python supports various OCR libraries like Pytesseract, utilizing Google's Tesseract-OCR engine. However, using Python to OCR PDF is a complex process.
Pytesseract can recognize text in PDFs across 100+ languages. Python's PDF OCR software versatility facilitates seamless integration with OCR libraries, enabling efficient autonomous handling of large datasets. Combined with machine learning techniques like NLP and object detection, Python empowers advanced computational capabilities.
Learn how to OCR PDF in Python using the Try and Except method.
Step 1: Import the necessary modules
Import `os` and `pytesseract` modules. Next, import the `Image` module from the `PIL` package. Use the `convert_from_path` function to convert PDF files to images for OCR processing with Python.
Step 2: The function takes a file name and initializes the empty list
The function takes one parameter (input file name) and initializes an empty list.
Step 3: Convert the text and generate a filename
In a try block, iterate through each image in the images list, converting it to text. Then, generate a filename for each image and save it as a JPEG.
Step 4: Extract text with pytesseract and handle exceptions
Extract text using pytesseract and append it to the list. Print exceptions encountered during these operations.
Step 5: Modify file extension to .txt format
Create output filename by removing input file extension and adding .txt extension.
Step 6: Assign a PDF file and return the filename
Assign input filename to `pdf_file`. Write extracted text to the output file with a modified extension. Next, return the output file name.
Step 7: Read and print the PDF output
Invoke `read_pdf` with `pdf_file,` and then print the output.
Extra Part: Run OCR on PDFs with Python Alternative
SwifDoo PDF is a versatile Windows editor that lets you OCR PDF in Python. It features an OCR engine that converts image-only PDFs into editable text. This makes it ideal for recognizing and manipulating text within scanned documents and images embedded in PDF files.
In addition, this reliable program allows you to annotate, edit PDFs, password-protect, and convert your documents with just one click.
Let's learn how to run OCR on PDF with the SwifDoo PDF program.
Step 1: Download and launch SwifDoo PDF from the official website or Microsoft AppSource for OCR capabilities.
Step 2: Launch the software and tap "OCR" in the Edit tab to begin.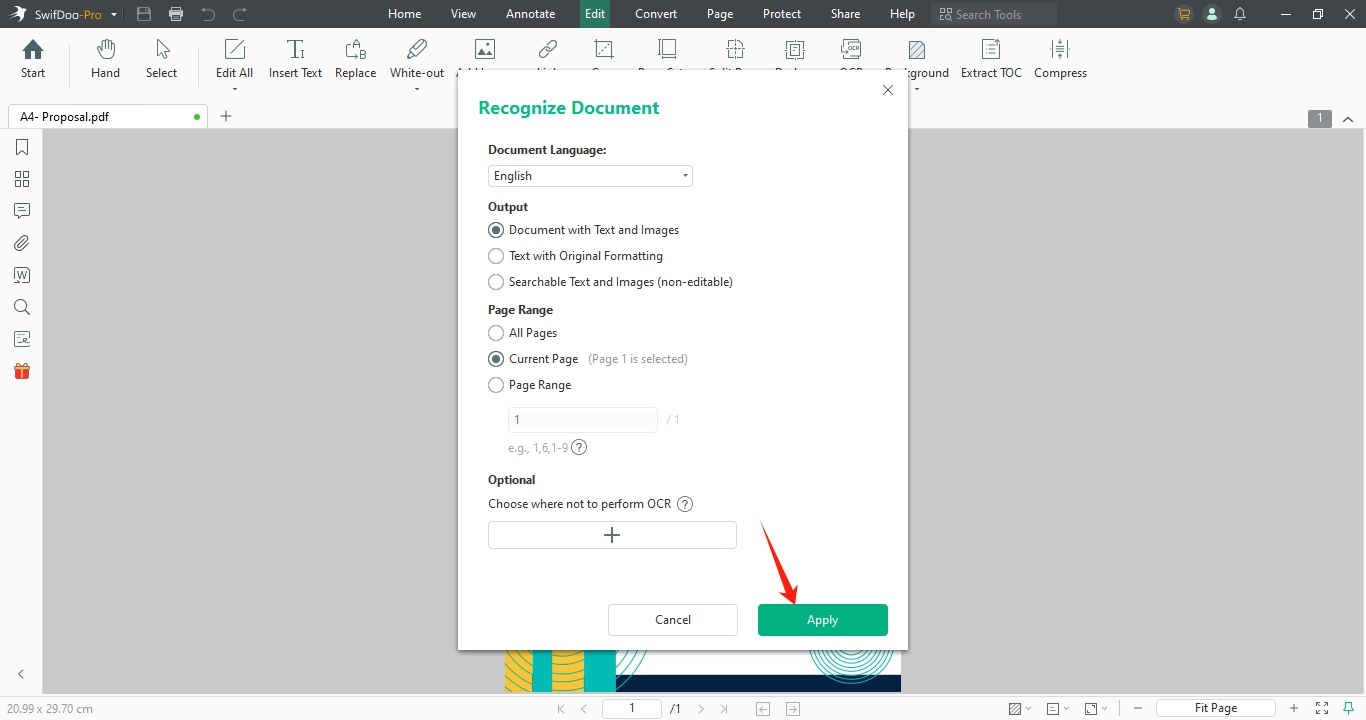
Step 3: In the Recognize Document window, select OCR options to convert PDFs to formats like text with images, original formatting, searchable non-editable text, or pure text.
Step 4: If necessary, specify page ranges when choosing the OCR output format. Click OK to initiate OCR processing of the PDF.
Final Wrap Up
Python's OCR libraries, such as EasyOCR, Tesseract, and Amazon Textract, automate tasks, streamline workflows, and extract insights from unstructured data. These libraries evolve with advancements in machine learning and computer vision to enhance capabilities across industries.
We have provided two ways to use Python to OCR PDF files. While the Try and Except method is a great technique, many users may find it complex to use. In such a case, you can rely on the professional expertise and ease of the SwifDoo PDF. It is a versatile and reliable way to manage all your PDF queries.


