



Ist das OCR ein neues Konzept für Sie? Keine Sorge. In diesem Beitrag erklären wir Ihnen ausführlich, was OCR ist, welche Software zur OCR-Erkennung es gibt und wie man eine PDF-Datei per OCR als Text erkennen kann, damit Sie Ihr PDF bearbeiten können.
Was ist PDF zu OCR?
OCR steht für Optical Character Recognition, ein Verfahren, bei dem PDF-Programme Bilder von Text in ein maschinenlesbares Format umwandeln. Diese weit verbreitete Technologie identifiziert den nicht durchsuchbaren Inhalt und extrahiert den Text aus einem reinen Bild-PDF oder einem gescannten PDF.
Einfach ausgedrückt, OCR ist eine fortgeschrittene Technologie, mit der man bearbeitbare PDF-Bildern in durchsuchbaren Text und Zeichen umwandelt.
Wie man per OCR gescannte PDFs mit Desktop-Software erkennt
SwifDoo PDF: PDF in OCR umwandeln Windows
SwifDoo PDF ist eine vielseitige OCR-Software für Windows. Als Multitasker kann es bei der PDF-Bearbeitung, dem Anbringen von Anmerkungen, dem Passwortschutz und der Konvertierung helfen. In der neuesten Version 2.0 verfügt SwifDoo PDF über eine brandneue Funktion – PDF OCR Erkennung, die PDF Text erkennen und ein PDF aus rein Bildern bearbeitbar macht.
Mit einer benutzerfreundlichen Oberfläche ist SwifDoo PDF auch für Anfänger einfach zu benutzen. Mit folgender Anleitung erfahren Sie, wie man mit PDF Texterkennung unter Windows durchgeführt:
Schritt 1: Klicken Sie auf die folgende Schaltfläche, um SwifDoo PDF kostenlos herunterzuladen;
Schritt 2: Starten Sie das Programm und öffnen Sie Ihre zu erkennende PDF-Datei. Gehen Sie dann auf „Bearbeiten“ > „OCR“ in der Hauptsymbolleiste.
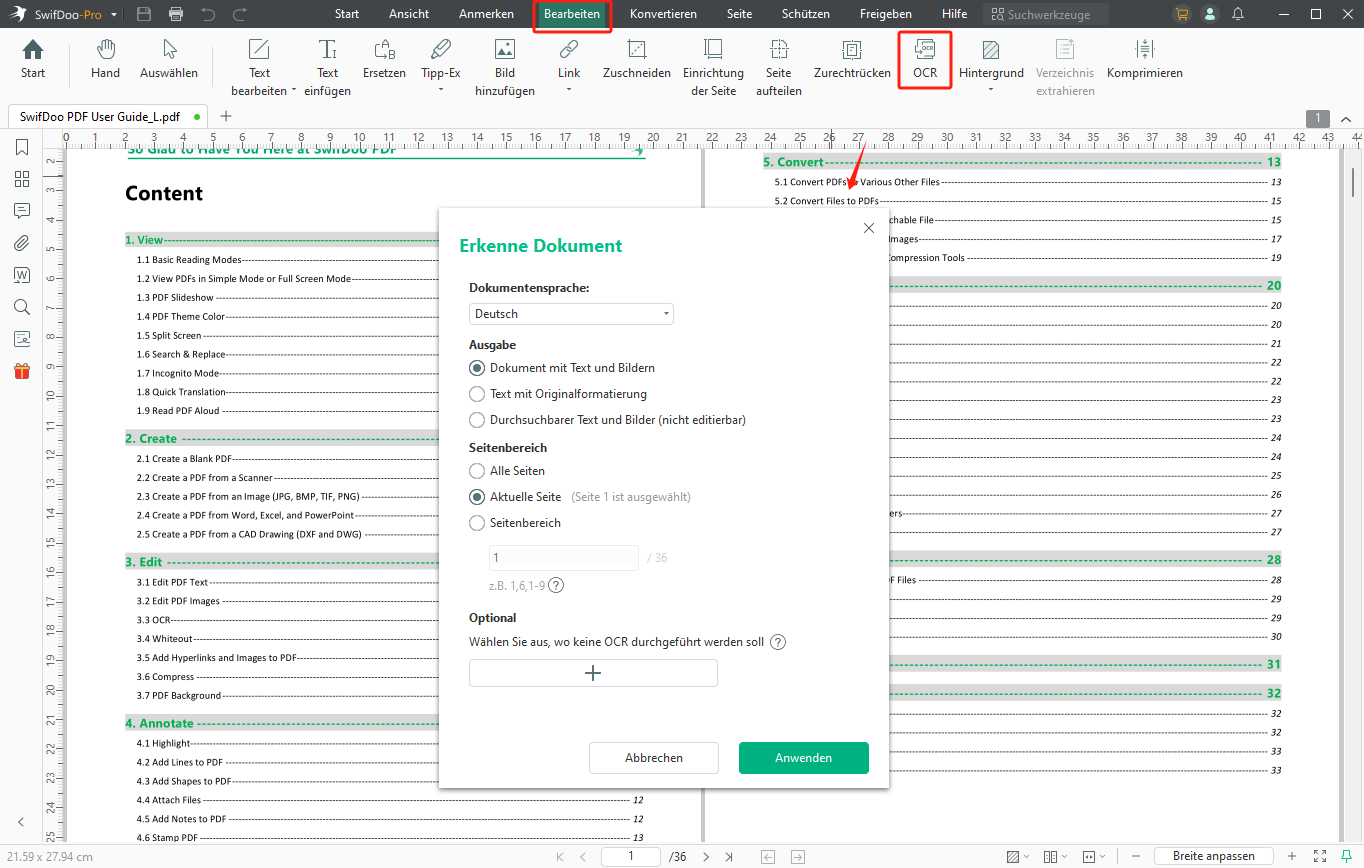
Schritt 3: Im Pop-up-Fenster können Nutzer wählen, wie das aktuelle PDF-Dokument per OCR erfasst werden soll und in ein Dokument mit Text und Bildern, Text mit Originalformatierung, durchsuchbaren Text und Bilder, aber nicht editierbar, oder einen reinen Text umgewandelt werden soll;
Schritt 4: Wenn Sie sich für die Ausgabeoption entschieden haben, können Sie bei Bedarf den Seitenbereich für die OCR angeben. Sobald Sie fertig sind, klicken Sie auf die Schaltfläche OK, um mit der OCR der PDF-Datei zu beginnen.
Wie stellt man sicher, ob die PDF-Datei aus Scans oder aus Bildern erstellt wird
Einige Nutzer fragen sich vielleicht, wie sie feststellen können, ob es sich bei einer PDF-Datei um ein gescanntes PDF oder ein reines Bild-PDF handelt und somit OCR erforderlich ist; hier sind zwei Lösungen:
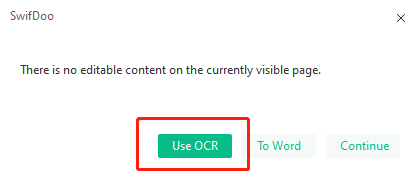
Lösung 1: Klicken Sie auf "Bearbeiten". Wenn ein Fenster erscheint, in dem kein bearbeitbarer Inhalt angezeigt wird, handelt es sich um eine gescannte PDF-Datei;
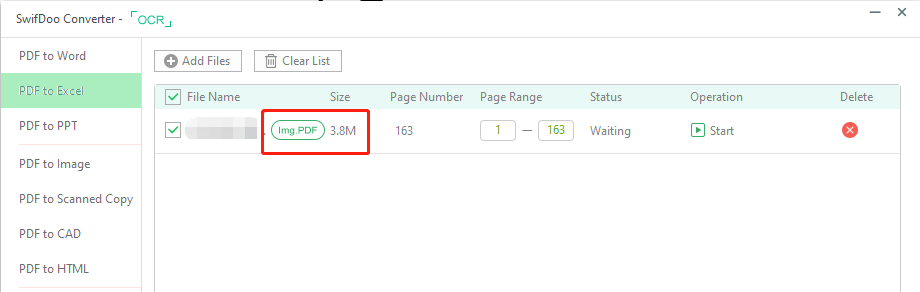
Lösung 2: Oder die Benutzer können PDF-Konvertierung-Aufgaben durchführen, indem sie auf "Konvertieren" klicken, z. B. die Konvertierung von PDF in Word. SwifDoo PDF kennzeichnet die Art des PDFs neben dem Dateinamen, wie der Screenshot zeigt.
Wenn Sie ein gescanntes PDF in Word oder eine Textdatei konvertieren müssen, kann das Ergebnis der Konvertierung enttäuschend sein, da das Word-Dokument nach der Konvertierung voller Fehler und falscher Formatierungen ist. Sie können jedoch optional versuchen, die PDF-Datei mit OCR zu bearbeiten, und die mit OCR bearbeitete PDF-Datei wird im selben lokalen Ordner gespeichert wie die Original-PDF-Datei.
Soda PDF: Text in PDF erkennen kostenlos
Soda PDF ist ein leistungsstarkes PDF-Tool, das die Arbeit mit PDF-Dateien erleichtern soll. Mit diesem Windows-basierten PDF OCR-Programm können Benutzer Wörter in PDF suchen, PDF-Seiten neu anordnen, mit Anmerkungen versehen und sichern. Sehen Sie sich an, wie Sie mit Soda PDF PDF-Bilder in durchsuchbaren Text umwandeln können:

Schritt 1: Laden Sie Soda PDF herunter und installieren Sie es auf Ihrem PC;
Schritt 2: Starten Sie das Programm und öffnen Sie die gescannte PDF-Datei;
Schritt 3: Wählen Sie OCR oder klicken Sie auf eine beliebige Seite der PDF-Datei, um den OCR-Modus zu aktivieren. Wenn Sie die hängende Menüleiste sehen, wählen Sie OCR Auto und die PDF wird von gescannten Bildern in einen auswählbaren und editierbaren Text umgewandelt.
Soda PDF bietet zwei OCR-Modi, um PDF-Bilder in durchsuchbaren Text zu konvertieren: OCR Auto und OCR Manual. Der Hauptunterschied zwischen diesen beiden Modi besteht darin, dass der Benutzer im letzteren entscheiden kann, wie die OCR-Engine mit seinen Bildern interagiert, während der Auto-Modus automatisch nach dem nächsten Bild sucht und es ebenfalls scannt. Die manuelle Erkennung kann Text, Bilder oder Tabellen in PDF erkennen. Jeder Bereich innerhalb dieses roten Kastens wird als Text interpretiert.
Da gescannte PDF-Dateien aus mehreren Bildebenen bestehen, bietet Soda PDF ein "Zuschneiden"-Werkzeug, mit dem man leere oder nicht notwendige Inhalte aus PDF-Seiten schneiden kann. In der Zwischenzeit können Benutzer jede Seite für den persönlichen Gebrauch verschieben oder kopieren, indem sie mit der rechten Maustaste auf das PDF-Bild klicken.
Wie man ein gescanntes PDF unter macOS per OCR erkennt
Cisdem PDF Converter OCR für Mac: PDF to OCR Converter
Für macOS-Anwender, die OCR auf PDF durchführen müssen, waren die Dinge komplizierter, bis wir Cisdem fanden. Cisdem und die dazugehörigen Produkte sind für Apple-Computer entwickelt worden, darunter auch das Herzstück dieses Abschnitts - Cisdem PDF Converter OCR für Mac.
Der Cisdem PDF Converter OCR integriert eine ganze Reihe von nützlichen Werkzeugen, um PDF-bezogene Aufgaben zu bewältigen, z. B. wie man ein gescanntes PDF unter macOS mit OCR versieht, wie man PDF-Dateien kombiniert und wie man PDF-Dateien im Stapel konvertiert. Ohne weitere Beschreibung kommen wir gleich zur Sache:
Schritt 1: Importieren Sie das reine Bild-PDF auf die Workstation, indem Sie die Datei auf die Oberfläche ziehen oder ablegen, auf die Schaltfläche + klicken oder Datei > Datei hinzufügen wählen;
Schritt 2: Wählen Sie die Sprache des Original-PDF-Dokuments, um die Erkennungsgenauigkeit zu verbessern. Cisdem unterstützt jetzt 27 Sprachen, die den grundlegenden Bedarf der Anwender decken können;
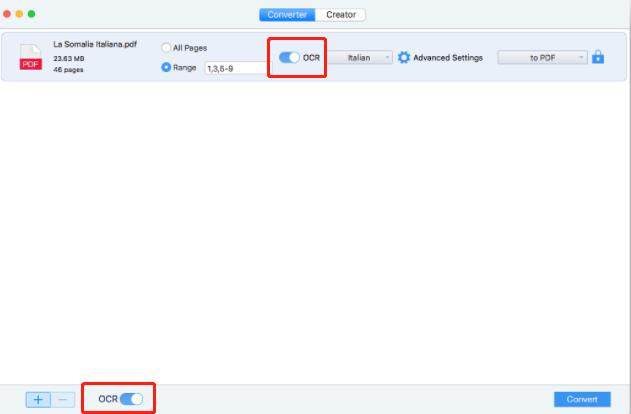
Schritt 3: Aktivieren Sie auf der Konverter-Seite das OCR-Kästchen, um die PDF-zu-OCR-Erkennung für das aktuelle PDF durchzuführen. Bitte beachten Sie, dass es zwei OCR-Schaltflächen gibt. Die Schaltfläche neben dem Bereich gilt nur für die ausgewählte PDF-Datei, während die andere Schaltfläche die OCR auf alle PDF-Dateien anwendet.
Schritt 4: Wählen Sie im Feld für das Ausgabeformat DOCX und klicken Sie auf die Schaltfläche Konvertieren. Wählen Sie dann den Ausgabeordner und klicken Sie auf "Speichern", um den Prozess der OCR einer PDF in eine Word-Datei auf dem Mac abzuschließen.
Darüber hinaus können Benutzer die Option "Erweiterte Einstellungen" wählen, um den erkannten Text, die Bilder oder Tabellen manuell anzupassen.
Da Cisdem kein PDF-Editor ist, können Sie keine Änderung in der erkannten PDF-Datei durchführen. Aber Sie können das kosten SwifDoo PDF für Mac benutzen, um PDF auf dem Mac anzuzeigen, bequem zu lesen, zum Papierdokument zu drucken oder das Anmerkung in PDF einfügen.
Wie man eine OCR einer gescannten PDF-Datei online erhält
Google Drive: Kostenlose PDF OCR Online
Für Leute, die OCR auf PDFs mit einer kostenlosen webbasierten PDF-OCR-Software anwenden möchten, kann diese Cloud-Speicherplattform eine gute Option sein. Es ist schwer vorstellbar, dass Google Drive in der Lage sein soll, eine solche Aufgabe zu erfüllen. Laut dem Google Drive-Hilfecenter ist diese Online-Anwendung jedoch in der Lage, Bilder in PDF zu erkennen und in Text zu konvertieren.
Schritt 1: Loggen Sie sich bei Ihrem Google Drive-Konto ein und klicken Sie auf die Schaltfläche Neu unterhalb des Drive-Symbols;
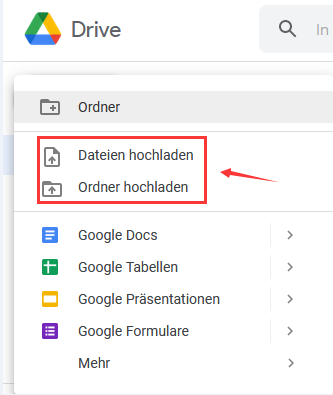
Schritt 2: Wählen Sie im Dropdown-Menü Datei Upload, um ein lokales PDF-Dokument in den Arbeitsbereich zu importieren;
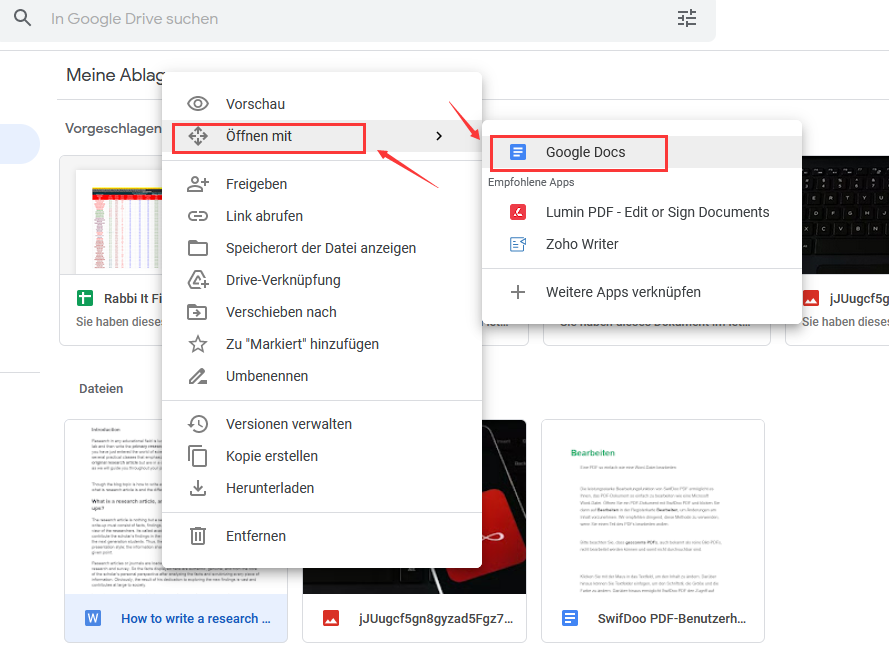
Schritt 3: Klicken Sie mit der rechten Maustaste auf das hochgeladene PDF-Dokument und wählen Sie Öffnen mit > Google Docs, um das gescannte PDF-Dokument in ein bearbeitbares Word-Dokument umzuwandeln. Wenn Sie auf die Google Docs-Seite geleitet werden, können Sie die Word-Datei lokal ausgeben.
Der Prozess der OCR-Erkennung eines PDF-Dokuments mit Google Drive ist zwar nicht kompliziert, aber es gibt einige Einschränkungen dieses kostenlosen Online-OCR-Tools, bevor Sie beginnen:
Dateigröße: Ihre Datei (.jpg, .png, .gif, oder PDF-Datei) sollte nicht größer als 2 MB sein;
Auflösung: Der Text sollte mindestens 10 Pixel groß sein;
Ausrichtung: Die Dokumente sollten mit der richtigen Seite nach oben ausgerichtet sein.
Schriftarten: Vergewissern Sie sich, dass die Schriftart in Ihrer Datei gängig ist, z. B. Arial oder Times New Roman.
OCR Space: OCR Texterkennung online
OCR Space ist eine kostenlose Online-OCR-Software. Gleichzeitig ist dieses nützliche Tool ein Open-Source-Programm, das einen kostenfreien OCR-API-Schlüssel für Entwickler bereitstellt. Als kostenloses Tool vereinfacht OCR Space den Konvertierungsprozess, so dass Benutzer nur ein paar Klicks machen müssen, um OCR auf ein PDF anzuwenden. Im Folgenden erfahren Sie, wie Sie ein PDF-Dokument online mit OCR erkennen können:
Schritt 1: Geben Sie die URL in die Suchleiste ein und wählen Sie Datei auswählen, um die PDF-Datei hochzuladen;
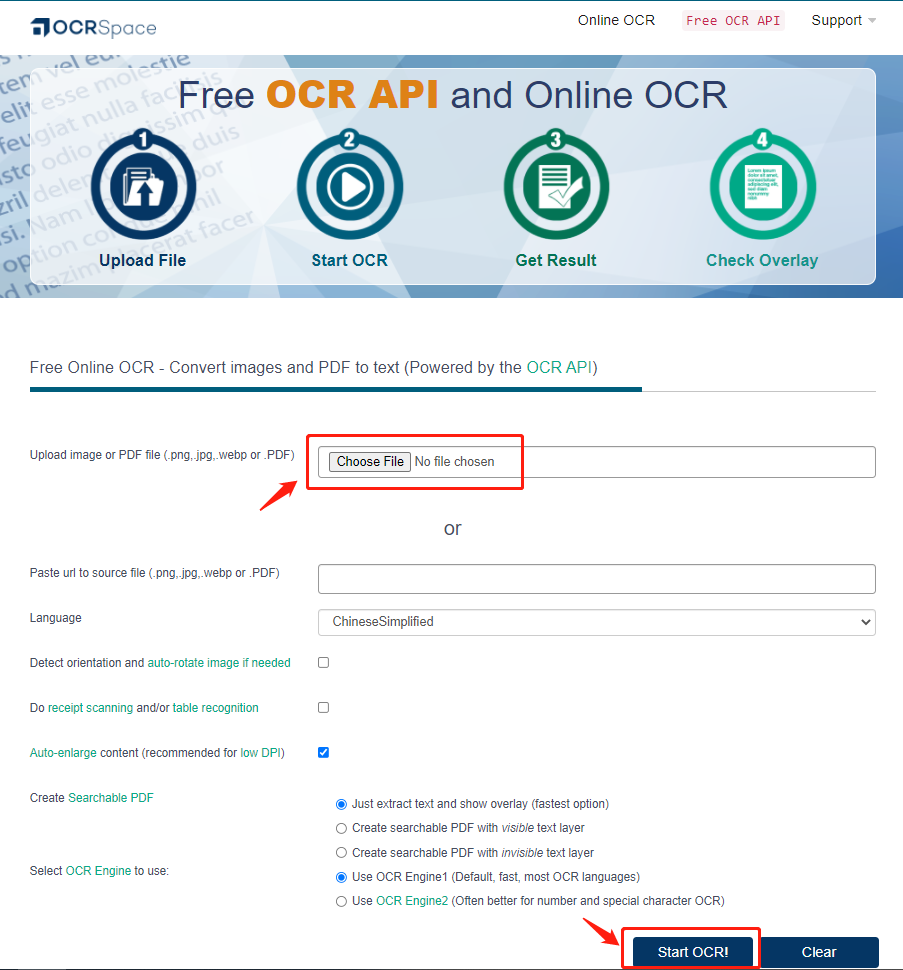
Schritt 2: Wählen Sie die Sprache des Original-PDF-Dokuments und kreuzen Sie bei Bedarf die Erkennung oder Ausrichtung an. Außerdem können Benutzer durchsuchbare PDFs erstellen, indem sie unter durchsuchbare PDF erstellen festlegen, wie die PDF angezeigt werden soll;
Schritt 3: Wenn Sie fertig sind, klicken Sie auf die Schaltfläche Start OCR!, um die gescannte PDF-Datei in ein wählbares DOCX-Dokument auszugeben. Wenn Sie nach OCR die PDF bearbeiten möchten, ist SwifDoo PDF nützlich.
Fazit
Abschließend lässt sich sagen, dass Online-OCR-Tools zwar gratis verwendet werden können, ihre OCR-Fähigkeiten aber möglicherweise von der OCR-Software für Desktop-PDFs in den Schatten gestellt werden, insbesondere wenn es sich um reine Bild-PDFs handelt, die in mehreren Sprachen verfasst sind (z. B. Lehrbücher). Um die OCR-Texterkennung mit der besten Qualität zu erzielen, ist SwifDoo PDF ein nützliches Tool. Das Programm ist leicht und umfassend. Es hilft Ihnen, alle PDF-Aufgaben mühelos zu erledigen und Produktivität zu entfalten.


